
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Android
- androidstudio
- bitmap
- BOJ
- Canvas
- CS
- Database
- DBeaver
- DP
- Ecilpse
- Eclipse
- firebase
- git
- github
- GooglePlayServices
- gradle
- IDE
- IntelliJ
- java
- json
- kotlin
- level2
- linux
- mariadb
- MYSQL
- Paint
- permission
- python
- Sorting
- sourcetree
will come true
[프로그래머스 / Level1] 동물 보호소 문제 모음 (1) (SQL) 본문
문제
https://programmers.co.kr/learn/courses/30/lessons/59405
코딩테스트 연습 - 상위 n개 레코드
ANIMAL_INS 테이블은 동물 보호소에 들어온 동물의 정보를 담은 테이블입니다. ANIMAL_INS 테이블 구조는 다음과 같으며, ANIMAL_ID, ANIMAL_TYPE, DATETIME, INTAKE_CONDITION, NAME, SEX_UPON_INTAKE는 각각 동물의 아이디
programmers.co.kr
- MIN, MAX
- COUNT
- GROUP BY, HAVING
- DATETIME
- SET
- IS NULL, IS NOT NULL
- CASE WHEN THEN, NVL, IFNULL
SQL문
--동물 보호소에 가장 먼저 들어온 동물의 이름
SELECT name
FROM animal_ins
WHERE datetime = (SELECT MIN(datetime)
FROM animal_ins);
--동물 보호소에 가장 최근에 들어온 동물이 들어온 날짜
SELECT MAX(datetime)
FROM animal_ins
--동물 보호소에 가장 먼저 들어온 동물이 들어온 날짜
SELECT MIN(datetime)
FROM animal_ins;
--동물 보호소에 들어온 동물의 수
SELECT COUNT(animal_id)
FROM animal_ins;
--동물 보호소에 들어온 동물의 수 (이름이 NULL이 아니며 중복은 제거할 것)
SELECT COUNT(DISTINCT name)
FROM animal_ins
WHERE name IS NOT NULL;
--동물 보호소에 들어온 동물 중 고양이와 개의 수
SELECT animal_type, COUNT(animal_id)
FROM animal_ins
GROUP BY animal_type
HAVING animal_type IN ('Cat', 'Dog')
ORDER BY animal_type;
--동물 보호소에 들어온 동물 이름 중 두 번 이상 쓰인 이름과 해당 이름이 쓰인 횟수
SELECT name, COUNT(name)
FROM animal_ins
GROUP BY name
HAVING COUNT(name) > 1
ORDER BY name;
--각 시간대별 입양횟수 (9~19시)
SELECT HOUR(datetime) AS HOUR, COUNT(*) AS COUNT
FROM animal_outs
GROUP BY HOUR(datetime)
HAVING HOUR BETWEEN 9 AND 19
ORDER BY HOUR
--각 시간대별 입양횟수 (0시~23시)
SET @hour := -1;
SELECT (@hour := @hour + 1) AS hour, (SELECT COUNT(*)
FROM animal_outs
WHERE HOUR(datetime) = @hour) AS count
FROM animal_outs
WHERE @hour < 23;
-- 이름이 없는 동물의 ID
SELECT animal_id
FROM animal_ins
WHERE name IS NULL
-- 이름이 있는 동물의 ID
SELECT animal_id
FROM animal_ins
WHERE name IS NOT NULL
-- 이름이 null일 경우 No name으로 출력
SELECT animal_type, IFNULL(name, 'No name'), sex_upon_intake
FROM animal_ins
ORDER BY animal_id
학습 내용
HAVING 과 WHERE 의 차이
WHERE 절과 HAVING절 모두 데이터를 필터링하는 조건절의 역할을 하지만, 두 구문은 실행되는 순서 및 대상이 다르다.
HAVING 절은 GROUP BY 뒤에 위치하며, GROUP BY로 그룹별 집계된 결과에 조건을 걸어 필터링한다.
참고로 GROUP BY를 사용하면 SELECT절에 'GROUP BY 기준 컬럼', '집계함수' 만 조회할 수 있기 때문에 HAVING절에서도 이 두 경우에 대해서만 조건을 설정할 수 있다. (집계함수에 사용되는 컬럼은 GROUP BY 컬럼이 아니더라도 사용 가능)
실행순서 : GROUP BY → HAVING
SELECT animal_type, COUNT(*)
FROM animal_outs
GROUP BY animal_type
HAVING animal_type IN ('Cat', 'Dog');
SELECT animal_type, COUNT(*)
FROM animal_outs
GROUP BY animal_type
HAVING COUNT(*) > 50;
WHERE 절은 GROUP BY로 인해 그룹별 집계가 되기 이전 원본데이터에 대해 조건을 걸어 필터링한다. 이때 WHERE절은 반드시 GROUP BY절 보다 위에 위치해야 한다.
실행순서 : WHERE → GROUP BY
SELECT animal_type, COUNT(*)
FROM animal_outs
WHERE animal_type IN ('Cat', 'Dog')
GROUP BY animal_type;
SELECT animal_type, COUNT(*)
FROM animal_outs
GROUP BY animal_type
WHERE animal_type IN ('Cat', 'Dog'); --WHERE절은 GROUP BY보다 위에 있어야 함
즉, HAVING절과 WHERE절을 함께 사용하면, WHERE → GROUP BY → HAVING 순으로 실행된다.
SELECT name, COUNT(*) --5) group by컬럼 name과 집계함수 결과 조회
FROM animal_outs --1) animal_outs테이블에서
WHERE animal_type = 'Dog' --2) animal_type이 Dog인 데이터만을 필터링
GROUP BY name --3) where로 필터링된 데이터를 name을 기준으로 그룹화
HAVING COUNT(*) > 1 --4) 그룹별 집계 건수가 1을 초과하는 데이터만 필터링
Datetime 날짜 및 시간 추출
[Oracle]
EXTRACT(추출값 FROM 컬럼명) 함수를 사용하여 구할 수 있으며
추출값이 날짜(YEAR, MONTH, DAY)이면 DATE컬럼을, 시간(HOUR, MINUTE, SECOND)이면 TIMESTAMP 컬럼을 넣는다.
DATETIME 타입 컬럼은 CAST(컬럼명 AS 타입) 을 통해 DATE 혹은 TIMESTAMP로 캐스팅 해서 사용한다.
--각 시간대별 입양횟수 (9~20시 이전)
SELECT EXTRACT(HOUR FROM CAST(datetime AS TIMESTAMP)) AS HOUR, COUNT(*) AS COUNT
FROM animal_outs
GROUP BY EXTRACT(HOUR FROM CAST(datetime AS TIMESTAMP))
HAVING EXTRACT(HOUR FROM CAST(datetime AS TIMESTAMP)) BETWEEN 9 AND 19
ORDER BY HOUR
[MySQL]
YEAR(), MONTH(), DAY(), HOUR(), MINUTE(), SECOND() 함수에 DATETIME 타입 컬럼을 넣어서 구한다.
--각 시간대별 입양횟수 (9~20시 이전)
SELECT HOUR(datetime) AS HOUR, COUNT(*) AS COUNT
FROM animal_outs
GROUP BY HOUR(datetime)
HAVING HOUR BETWEEN 9 AND 19
ORDER BY HOUR
위의 방법이 정석이지만 TO_CHAR() 함수를 이용해 날짜를 형식화된 문자열로 변환할 수도 있다.
다만 이 방법에서는 TO_CHAR(datetime, 'HH24')의 결과 시간을 0~24의 형태로 표시하기 때문에 문제에서 주어진 기대 결과와 달리, HOUR이 '9'가 아니라 '09'로 표시된다. = 0을 없애는 방법이 있을 거 같긴 하지만 일단 기각..
SELECT TO_CHAR(datetime, 'HH24') AS HOUR, COUNT(*) AS COUNT
FROM animal_outs
GROUP BY TO_CHAR(datetime, 'HH24')
HAVING TO_CHAR(datetime, 'HH24') BETWEEN 9 AND 19
ORDER BY HOUR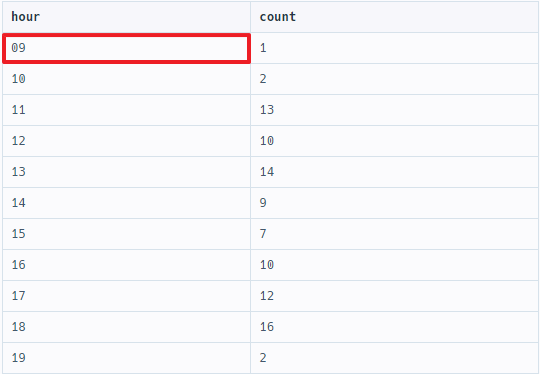
계층형 구조
상하 수직관계의 트리형태(노드간의 연결)의 구조로, 데이터가 서로 부모-자식 관계로 연결되어 있다.
- 카테고리 : 가구 > 거실가구 > 소파 > 좌식소파
- 회사 조직도 : 회사(CEO) > 서울본사 > 경영지원본부 > 전산팀
- 학과 : ○○대학교 > ◇◇캠퍼스 > 공과대학 > 컴퓨터공학부
계층형 쿼리
테이블에 저장된 데이터를 부모-자식 관계의 계층형 구조로 반환하는 쿼리이다.
SELECT [컬럼명][LEVEL]
FROM [테이블명]
WHERE [조건절]
START WITH [루트 노드 조건]
CONNECT BY [NOCYCLE][PRIOR 계층 구조 조건];- START WITH 절
: 루트 노드로 사용할 노드 식별 조건 ex) PARENT_DEP_CD IS NULL : 최상위 노드는 부모가 없음 - CONNECT BY 절
: PRIOR과 함께 부모노드와 자식노드 컬럼간의 연결 관계 규정 ex) PRIOR DEP_CD = PARENT_DEP_CD
- CONNECT BY PRIOR 자식컬럼=부모컬럼 : 부모에서 자식으로 트리구성 (Top Down)
- CONNECT BY PRIOR 부모컬럼=자식컬럼 : 자식에서 부모로 트리구성 (Bottom Up)
- PRIOR
: 상위행의 컬럼임을 명시 - NOCYCLE
: 무한 루프 방지 - LEVEL
: 레벨 의사컬럼(LEVEL Pseudocolumn), 계층 구조에서 현재 컬럼의 깊이(Depth)
LPAD(' ', 2*(LEVEL-1)) : 레벨별 들여쓰기, Depth가 깊을수록 더 많이 들여쓰기 된다. - ORDER SIBLINGS BY
: 계층구조 쿼리 정렬 - LEAF
: 해당 데이터가 단말 노드인지 여부를 판단 - 루트 노드(root node)
: 부모가 없는 노드 =최상위 노드 - 단말 노드(leaf node)
: 자식이 없는 노드 =최하위 노드 - 실행 순서 : START WITH → CONNECT BY → WHERE
SET 명령어
- SET @변수명 = 값;
- 대입은 :=, 동등 비교는 =
SET @hour := -1; --변수 선언
SELECT (@hour := @hour + 1) AS hour --(-1~22까지 +1을 더한 값 = 0~23)을 출력
FROM animal_outs
WHERE @hour < 23;
입양 시간 구하기 (2)
0시 부터 23시 까지 시간대별 입양횟수를 구하는 문제인데, 자료로 주어진 animal_outs 테이블에는 7시~19시까지의 데이터만 존재한다. (입양을 진행한 시간대가 9시~19시 뿐) 그렇기 때문에 0시~6시, 20시~23시의 HOUR을 별도로 만들어줘야 한다. 이때 SET명령어를 사용해 0~23의 데이터를 가지는 테이블을 인위적으로 만들어주고, 해당 테이블과 animal_outs 테이블에서 HOUR의 값이 같은 것들만 COUNT해서 출력한다. SELECT문에 서브쿼리를 넣는 것. LEFT OUTER JOIN을 통한 방법도 존재할 것 같은데, 일단 변수를 이용한 방법이 제일 간단해 보여서 아래와 같이 풀이.
SET @hour := -1;
SELECT (@hour := @hour + 1) AS hour, (SELECT COUNT(*)
FROM animal_outs
WHERE HOUR(datetime) = @hour) AS count
FROM animal_outs
WHERE @hour < 23;

NULL 값 처리하기
1. CASE WHEN 조건 THEN 결과 ~ ELSE 결과 END
-- 이름이 null일 경우 No name으로 출력
SELECT animal_type, CASE WHEN name is null THEN 'No name'
ELSE name END name, sex_upon_intake
FROM animal_ins
ORDER BY animal_id
2. Oracle
- NVL(컬럼명, NULL일 경우 반환값) *NULL이 아닐 경우 컬럼값 반환
- NVL2(컬럼명, NULL이 아닐 경우 반환값, NULL일 경우 반환값)
-- 이름이 null일 경우 No name으로 출력
SELECT animal_type, NVL(name, 'No name'), sex_upon_intake
FROM animal_ins
ORDER BY animal_id
3. My SQL
- IFNULL(컬럼명, NULL일 경우 반환값)
-- 이름이 null일 경우 No name으로 출력
SELECT animal_type, IFNULL(name, 'No name'), sex_upon_intake
FROM animal_ins
ORDER BY animal_id
내용이 너무 길어져서 게시글을 분리하도록 함
[참고자료]
- 프로그래머스 코딩테스트 연습 SQL문제, https://programmers.co.kr/learn/courses/30/lessons/59405
- Kaggle "Austin Animal Center Shelter Intakes and Outcomes", https://www.kaggle.com/aaronschlegel/austin-animal-center-shelter-intakes-and-outcomes
'Database' 카테고리의 다른 글
| [MariaDB] DBeaver 설치 및 기본 세팅 + MariaDB 연결하기 (0) | 2021.08.28 |
|---|---|
| [MariaDB] MariaDB 설치 및 접속하기 (0) | 2021.08.27 |

